https://machinereads.com/2018/09/26/attention-is-all-you-need/
Attention Is All You Need
: Google에서 발표한 논문 Attention is all you need(NIPS)에서 소개한 모델 Transformer는 현재 best NLP model이라고 주목받는 BERT의 모듈로도 사용되었다.
Seq2Seq Machine Translation(기계번역)
Transformer 이전의 seq2seq 모델은 Reccurent Neural Network(RNN) 또는 Convolution Neural Network(CNN)을 encoder, decoder로써 활용하여 sequential 한 input과 output을 처리했다.
하지만 이 모델들은 기본적으로 1)상당한 계산복잡도를 가지며,
2)RNN의 경우 layer내에서의 병렬처리가 불가능하고(sequential한 처리만 순차적으로 가능),
output으로 하나의 단어를 생성해낼 때 3)lone-range dependency를 가진 정보를 참조하는 경우, 이 정보가 긴 path를 거쳐 전달된다는 단점이 있다.
Reccurent Neural Network
여러 hidden layer를 거치면서 번역할 정보가 희석되어 해석이 정확하지 않을 수 있음.

RNN with attention
이를 극복하기 위해 제안된 모델이 Atttention을 사용하는 모델이다.

Input sentence 각각의 단어에 해당하는 hidden layer와 당장 출력해야하는 단어의 연관성을 기반으로 내가 지금 참조해야하는 source에 더 집중하여 정보를 가져오는 모델임.
관련도가 높은 source 단어에 더 가중치를 두어 output 단어를 계산한다.
하지만, layer 내에서 병렬 처리가 불가능한 RNN모델에, attention 계산까지 더해져서 계산 복잡도가 하늘로 솟구치게 된다.
=> 논문의 저자들이 제기한 의문 : attention을 통해 참조해야할 source의 위치(position)을 알 수 있다면, 굳이 sequence를 고려할 필요가 있을까? 굳이 계산 복잡도가 높은 RNN모델을 사용할 필요가 있을까?

=> 오직 input과 이전 output값들의 attention만을 이용하여 다음 단어를 출력하여 계산 복잡도를 줄일 수 없을까?
Self-attention
기존 attention 모델이 output을 출력할 때만 attention을 이용했다면,
Transformer은 sequence내에서 단어 간의 관계 정보를 self-attention을 이용해 미리 계산해 놓는다.
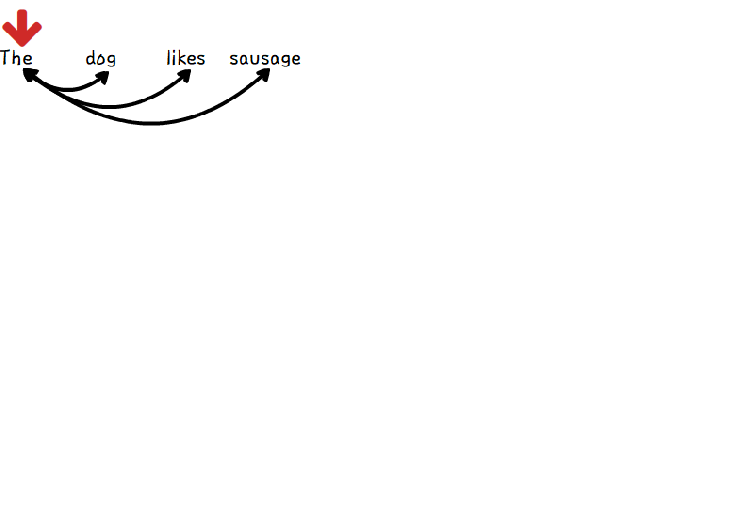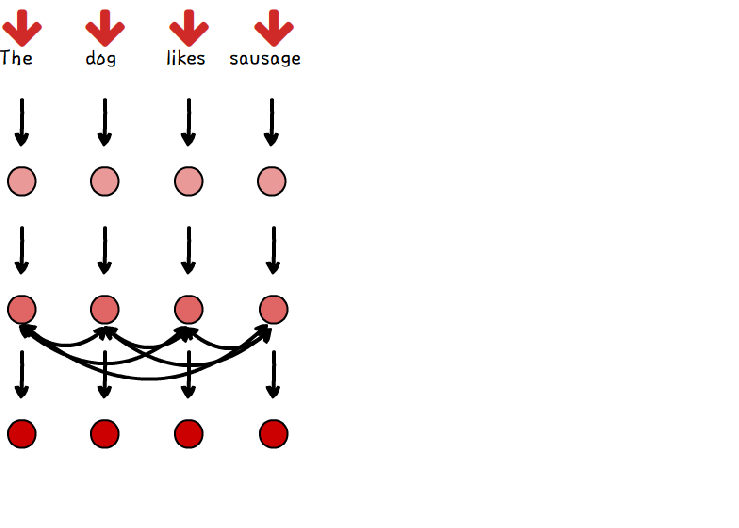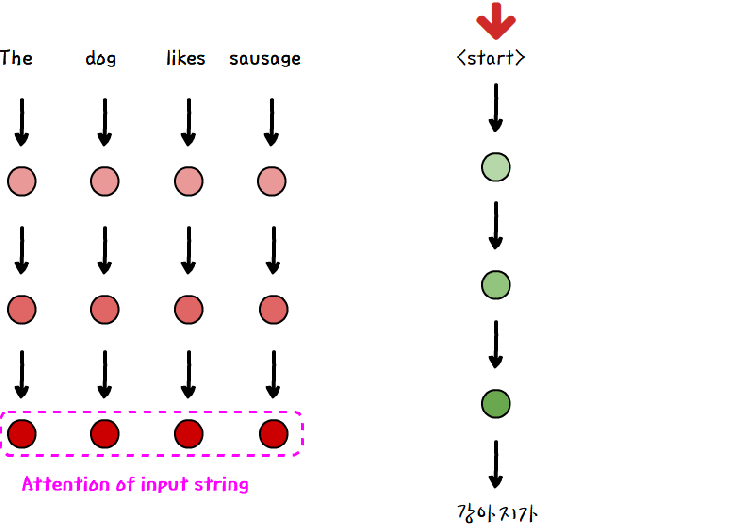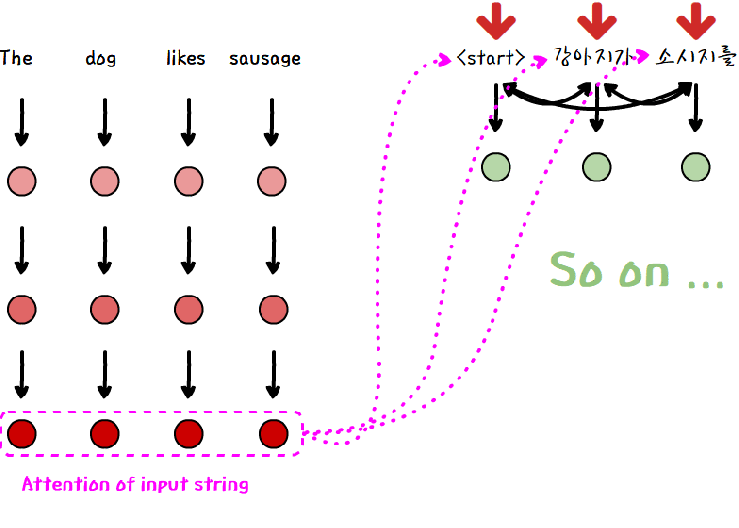
=> Transformer는 RNN과는 달리 병렬 계산이 가능하다. input sequence에 대해선 output을 계산하기 이전에 병렬로 attention 계산을 끝내놓는다. 그리고 나서 output 단어를 계산할 때에는 출력할 단어 이전 단어들의 attention과 미리 계산한 input의 attention을 이용해 다음 단어를 예측한다.

위의 표는 RNN, CNN, Self-Attention의 계산 복잡도를 비교한 것.
대부분의 경우 한 문장에서 단어의 개수는 모델의 dimension에 비해 월등히 작기 때문에 엄청난 계산적 이득을 얻는다고 볼 수 있다.
Transformer

RNN을 포기하는 대신 문장 내에서 단어의 순서 정보를 담기 위해 positional encoding 과정을 거친 후 input sentence와 출력할 단어 이전의 output 단어들은 Encoder와 Decoder로 보내진다.
Encoder와 Decoder에는 각각 6개씩 layer가 있으며, 하나의 layer 안에선 단어 사이의 관계 추출(self-attention), 단어 예측에 필요한 attention추출(decoder에만 적용), 문장 내의 정보 추출 (feed forward network)의 프로세스가 진행된다.
Encoder 마지막 layer의 결과물이자 input sentence의 attention은 Decoder의 모든 layer에서 사용되며, Decoder의 마지막 layer 의 output은 선형변환과 softmax layer를 거쳐 단어를 예측한다.
positional encoding
Input sentenc와 output 단어들은 모두 embedding 후, 문장 내에서의 위치 정보를 담기 위해서 positional encoding 과정을 거친다.
Position encoding은 position을 나타내주는 vector를 각각의 단어에 더해주는 방식으로 진행된다.
이 position vector는 주기함수의 조합으로 이루어지는데, 문장의 앞쪽에 위치할수록 값이 커진다.
=> ex) 문장을 반으로 나누었을 때 전반부에 위치하면 첫번재 position vector 값이 1 후반부이면 0이다. 만약 해당 단어가 전반부에 위치해 첫번째 값이 1이라면 그 다음 값들을 통해 전반부 내에서도 자세하게 어디에 위치하는지 파악할 수 잇다.
Positional encoding이 끝나면 Encoder 혹은 Decoder layer 에 입력된다.
Scaled Dot-Product Attention
Transformer 에서 Attention을 구하는 가장 작은 단위는 Scaled Dot-Product Attention이다.

Scaled Dot-Product Attention을 이루는 component 중에서 mask와 scale을 생략하고 살펴보면,
두 개의 MAtrix(K, Q)의 연산을 이용하여 나머지 Matrix(V) 내의 정보를 추출하는 과정임을 알 수 있다.
편의상 Q를 vector로 표현하자. 먼저 K와 Q를 Dot-Product 하게 되면 K를 구성하는 각각의 vectr와 Q vector의 Dot-product라고 생각할 수 있다. 이때 Q와 유사한 K의 row vector의 연산값이 높게 나타날 것이다. 그 후 이 결과 값에 softmax를 취하게 되면 Q와 유사한 K의 row가 무엇인지 확률의 형태로 나타날 것이다.
K의 각각의 row vector는 V의 각각의 row에 대한 key index로 생각해보자. 추출하고자 하는 정보가 나이에 대한 정보일 때, Q에 요구하는 index정보(Age)를 담아 K와 dot product 후 softmax를 취한다. 이 때, K의 row 중 어떤 것을 요구(Q)하는지 확률의 형태로 나타나게 되고, 이 확률 값과 V를 dot-product하면 원하는 정보를 추출 할 수 있다.
Multi-head Attention
여기서 V, K, Q 를 여러 다른 차원으로 projection시킨 후 각각 위의 Scaled Dot-Product Attention에 적용하여 합친 결과를 뽑아내는 것이 Multi-head Attention이다.
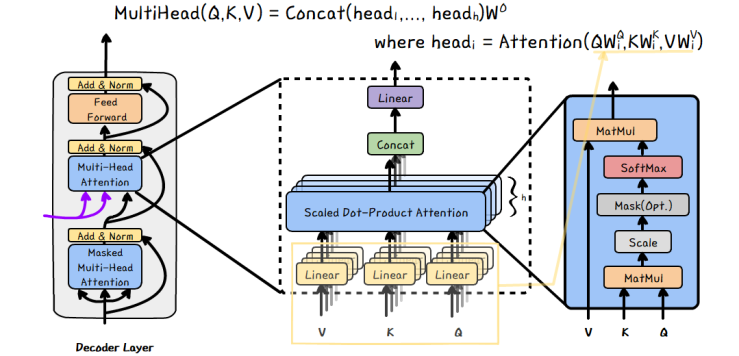
V, K, Q각각을 h번 다른 linear projection을 통해 변환시키고 병렬로 각각의 attention을 계산한다. 이를 concatenation 한 후 다시 선형 변환을 통해 최종 값을 계산한다.
Position-wise Feed-Forward Network
Attention을 통해 단어 사이의 dependency 등을 구했다면, layer 2개 짜리 Neural Net으로 기존 RNN이나 CNN의 역할을 대체한다. CNN이 N size kernel의 조절을 통해 N-gram 정보를 추출할 수 있었다면, Trnasformer 는 1-size kernel 만으로 문장 전체의 정보를 추출 할 수 있게 된다.
Result
<English Constituency Parsing>
Transformer모델을 Machine translation의 용도로 제안되었지만, 따로 task-specific tuning 없이도 다른 seq2seq 모델에 적용될 수 있다.
<Machine Translation Task(EN-DE & EN-FR)>
Machine translation에서는 BLEU score에서 괄목할만한 성능향상을 보인 것은 아니지만, traing cost 측면에서는 100배 정도의 cost efficiency를 보인 것을 확인할 수 있다.
Attention Visualization